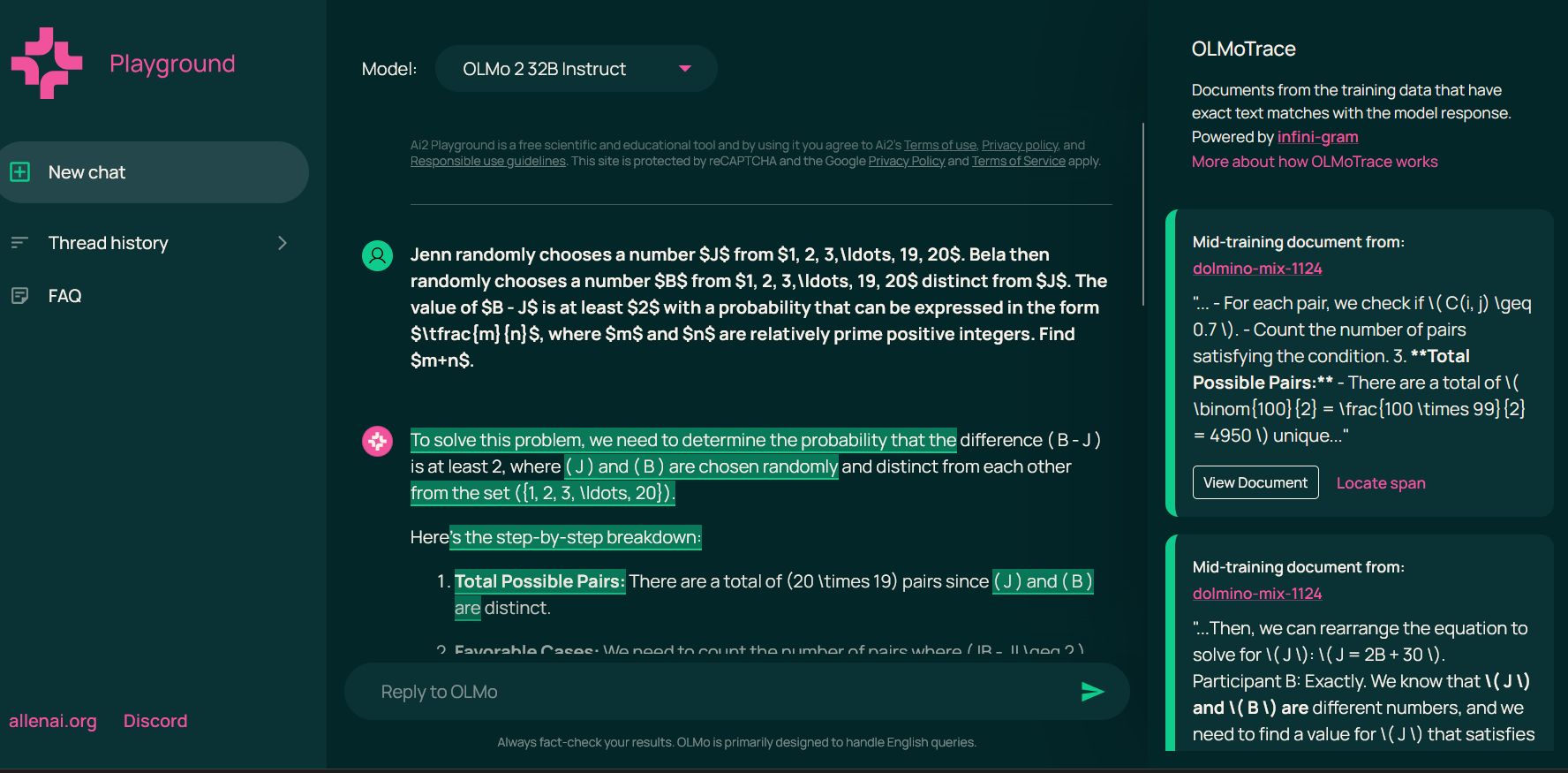
AI2’s OLMoTrace lets you trace an LLM output back to verbatim spans in its training corpus in seconds, which opens up better fact-checking, hallucination diagnosis, and a much more concrete way to reason about what a model is actually doing.
Explainability becomes much more practical when model behavior can be inspected through concrete evidence rather than inference alone.
Why It Matters
Once you can see whether a response is reproduced, recombined, or seemingly invented, you get a much better handle on fact-checking, hallucination analysis, memorization risk, and the practical boundaries of model transparency.
Potential Use Cases
- Fact-checking and verification for surprising model claims.
- Hallucination diagnosis when you need to separate memorization from invention.
- Creative-writing provenance for understanding reuse versus novelty.
- Math and code tracing when exact overlaps matter.
- Bias and privacy auditing for memorized sensitive spans.
What I Find Interesting
The most compelling part is not only the tracing itself, but the way it changes how we talk about model behavior. It gives engineers and researchers a more concrete debugging surface and pushes the conversation away from pure abstraction.
What’s Novel
- Real-time matching at very large corpus scale.
- More efficient indexing and span finding than naive search.
- Disk-based infrastructure that avoids huge RAM-heavy setups.
Limitations
- Exact-match only, so paraphrases are outside scope.
- Literal overlap, not semantic similarity.
Takeaway
Tools like this make explainability feel less like a vague ideal and more like a practical engineering direction. That is exactly the kind of AI tooling I want to see more of.